Table of Contents
BDMPI is a message passing library and associated runtime system for developing out-of-core distributed computing applications for problems whose aggregate memory requirements exceed the amount of memory that is available on the underlying computing cluster. BDMPI is based on the Message Passing Interface (MPI) and provides a subset of MPI's API along with some extensions that are designed for BDMPI's memory and execution model.
A BDMPI-based application is a standard memory-scalable parallel MPI program that was developed assuming that the underlying system has enough computational nodes to allow for the in-memory execution of the computations. This program is then executed using a sufficiently large number of processes so that the per-process memory fits within the physical memory available on the underlying computational node(s). BDMPI maps one or more of these processes to the computational nodes by relying on the OS's virtual memory management to accommodate the aggregate amount of memory required by them. BDMPI prevents memory thrashing by coordinating the execution of these processes using node-level co-operative multi-tasking that limits the number of processes that can be running at any given time. This ensures that the currently running process(es) can establish and retain memory residency and thus achieve efficient execution. BDMPI exploits the natural blocking points that exist in MPI programs to transparently schedule the co-operative execution of the different processes. In addition, BDMPI's implementation of MPI's communication operations is done so that to maximize the time over which a process can execute between successive blocking points. This allows it to amortize the cost of loading data from disk over the maximal amount of computations that can be performed.
Since BDMPI is based on the standard MPI library, it also provides a framework that allows the automated out-of-core execution of existing MPI applications. BDMPI is implemented in such a way so that to be a drop-in replacement of existing MPI implementations and allow existing codes that utilize the subset of MPI functions implemented by BDMPI to compile unchanged.
A detailed description of BDMPI's design along with an experimental evaluation of the performance that it can achieve can be found in [1], [2] (also included in BDMPI's source distribution). In the rest of this section we provide a brief overview of some of its elements as well as the key changes that have been included since that work was published.
Motivation of the approach
The general approach used by out-of-core algorithms is to structure their computations into a sequence of steps such that the working set of each step can fit within the available physical memory and the data associated with each step can be loaded/stored from/to the disk in a disk-friendly fashion (e.g., via sequential accesses or via a small number of bulk accesses).
Scalable distributed memory parallel algorithms decompose the computations into different tasks and each task along with its associated data is mapped on the available compute nodes. This decomposition is optimized so that it maximizes the computations that can be done with the local data (i.e., maximize locality) and reduce the frequency as well as the volume of the data that needs to be communicated across the nodes (i.e., minimize communication overheads). In addition, most of these algorithms structure their computations into a sequence of phases involving a local computation step followed by inter-process communication step.
BDMPI relies on the observation that a scalable distributed memory parallel algorithm can be transformed into an algorithm whose structure is similar to that used by out-of-core algorithms. In particular, if 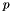 is the number of processes required to ensure that the per-process memory fits within the compute node's available physical memory, then the computations performed by each process in a single phase will correspond to a distinct step of the out-of-core algorithm. That is, one parallel phase will be executed as sequential steps. Since the working set of each of these steps fits within the physical memory of a node, the computations can be performed efficiently. Moreover, if the underlying computational infrastructure has
is the number of processes required to ensure that the per-process memory fits within the compute node's available physical memory, then the computations performed by each process in a single phase will correspond to a distinct step of the out-of-core algorithm. That is, one parallel phase will be executed as sequential steps. Since the working set of each of these steps fits within the physical memory of a node, the computations can be performed efficiently. Moreover, if the underlying computational infrastructure has 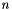 available nodes, each node will perform
available nodes, each node will perform 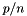 of these steps in sequence, leading to a distributed out-of-core execution.
of these steps in sequence, leading to a distributed out-of-core execution.
BDMPI performs this transformation in a way that is entirely transparent to the programmer. It uses the OS's virtual memory management (VMM) mechanisms to provide the programmer with the illusion that the parallel program is operating as if all the data fits in memory and, when appropriate, uses disk-based message buffering to ensure the correct and efficient execution of the communication operations.
Execution & memory model
BDMPI uses two key elements in order to enable efficient out-of-core execution. The first relates to how the MPI processes are executed on each node and the second relates to the memory requirements of the different MPI processes. The first is called the execution model and the second is called the memory model.
BDMPI's execution model is based on node-level co-operative multi-tasking. BDMPI allows only up to a fixed number of processes to be executing concurrently with the rest of the processes blocking. When a running process reaches an MPI blocking operation (e.g., point-to-point communication, collective operation, barrier, etc.), BDMPI blocks it and selects a previously blocked and runnable process (i.e., whose blocking condition has been satisfied) to resume execution.
BDMPI's memory model is based on constrained memory over-subscription. It allows the aggregate amount of memory required by all the MPI processes spawned on a node to be greater than the amount of physical memory on that node. However, it requires that the sum of the memory required by the processes that are allowed to run concurrently to be smaller than the amount of physical memory on that node. Within this model, an MPI program will rely on BDMPI's and OS's VMM mechanisms to load in memory the data needed by each process in a way that is transparent to the running program.
The coupling of constrained memory over-subscription with node-level co-operative multi-tasking is the key that allows BDMPI to efficiently execute an MPI program whose aggregate memory requirements far exceed the aggregate amount of physical memory in the system. First, it allows the MPI processes to amortize the cost of loading their data from the disk over the longest possible uninterrupted execution that they can perform until they need to block due to MPI's semantics. Second, it prevents memory thrashing (i.e., repeated and frequent page faults), because each node has a sufficient amount of physical memory to accommodate all the processes that are allowed to run.
Master & slave processes
The execution of a BDMPI program creates two sets of processes. The first are the MPI processes associated with the program being executed, which within BDMPI, they are referred to as the slave processes. The second is a set of processes, one on each node, that are referred to as the master processes. The master processes are at the heart of BDMPI's execution as they spawn the slaves, coordinate their execution, service communication requests, perform synchronization, and manage communicators.
The master processes are implemented by a program called bdmprun, which is a parallel program written in MPI (not BDMPI). When a user program is invoked, bdmprun is first loaded on the nodes of the cluster and then proceeds to spawn the slave processes. Section Running BDMPI Programs provides detailed information on how to use bdmprun to start a BDMPI program.
Efficient loading & saving of a process's address space
The initial implementation of BDMPI ([1] and [2]), explored three different approaches for saving and/or restoring the address space of a slave process. The first approach relied entirely on the OS's VMM system to save/load the unused/used pages from the system's swap file. The second approach incorporated application-directed prefetching by relying on the mlock() system calls to lock in physical memory parts of the address space. Finally, the third bypassed the swap file entirely by requiring the application to explicitly save/load the various data structures that it needs to/from a file. The first approach is entirely transparent to the programmer, whereas the last two approaches require that the programmer modifies his/her program in order to either insert the appropriate mlock()/munlock() calls or explicitly perform file I/O. However, the gains achieved by the last two approaches were often considerable, with the third approach performing the best.
The current implementation of BDMPI uses its own memory allocation subsystem that is designed to achieve the performance of explicit file I/O with no or minimal modifications of the underlying program. This memory management subsystem, which is referred to as storage-backed memory allocation and will be abbreviated as sbmalloc, is implemented as a wrapper around libc's standard malloc() library. That is, a call to malloc() in a BDMPI program will be performed by sbmalloc. BDMPI provides wrappers for the following malloc-related functions: malloc(), realloc(), and free(). Note that calloc() is not in that list due to an issue with GNU libc's implementation of dlsym(), which prevents calloc() to be wrapped.
The key ideas behind sbmalloc are the following:
- It uses
mmap()to satisfy an allocation request and creates a file that will be used to persist the data of the associated memory pages when the slave is blocked. - It relies on memory protection and signal handling to determine if the program is accessing any of the allocated pages and if so, the access mode (read or write).
- It saves any pages that have been modified to its associated file when the slave process blocks due to a communication operation and
- informs the OS that the associated address space does not need to be saved in the swap file, and
- modifies the memory protection of the associated pages to remove read/write permissions.
- When a process first reads anywhere in the allocation, it reads the previous data from the disk for the entire allocation (if they exist) and gives the process read permissions to the allocation.
As a result of the above, if the aggregate amount of memory that the running slaves need to access between successive blocking operations fits within the physical memory of the node, these allocations will not use the system's swap file. The advantage of this approach is that as long as the application tends to read and/or write all the data within an allocation request, this data will be brought into memory and saved with fast sequential read/write operations.
Section Options related to memory resources provides additional information on how to control which memory allocations will be handled by sbmalloc and which ones will be handled by the standard malloc library. Section Storage-backed memory allocations provides information on how to explicitly use the sbmalloc subsystem in a program. Finally, Issues related to sbmalloc provides information on some issues that may arise with sbmalloc and how to resolve them.
